
Scaling Systems
"Keeping things simple and yet scalable is actually the biggest challenge."
Urs Hölzle, 2011, Senior VP of technical infrastructure and Google Fellow at Google
In our journey of implementing machine learning in finance, we did not anticipate is the amount of complexity introduced when things are required to happen at scale.
Even something super simple becomes complex at scale.
Take the example of reading an email, which is considered a simple task. Reading a 100 emails a day takes a bit longer but still remain a simple task. Reading a 100 million emails needs a complete new approach.
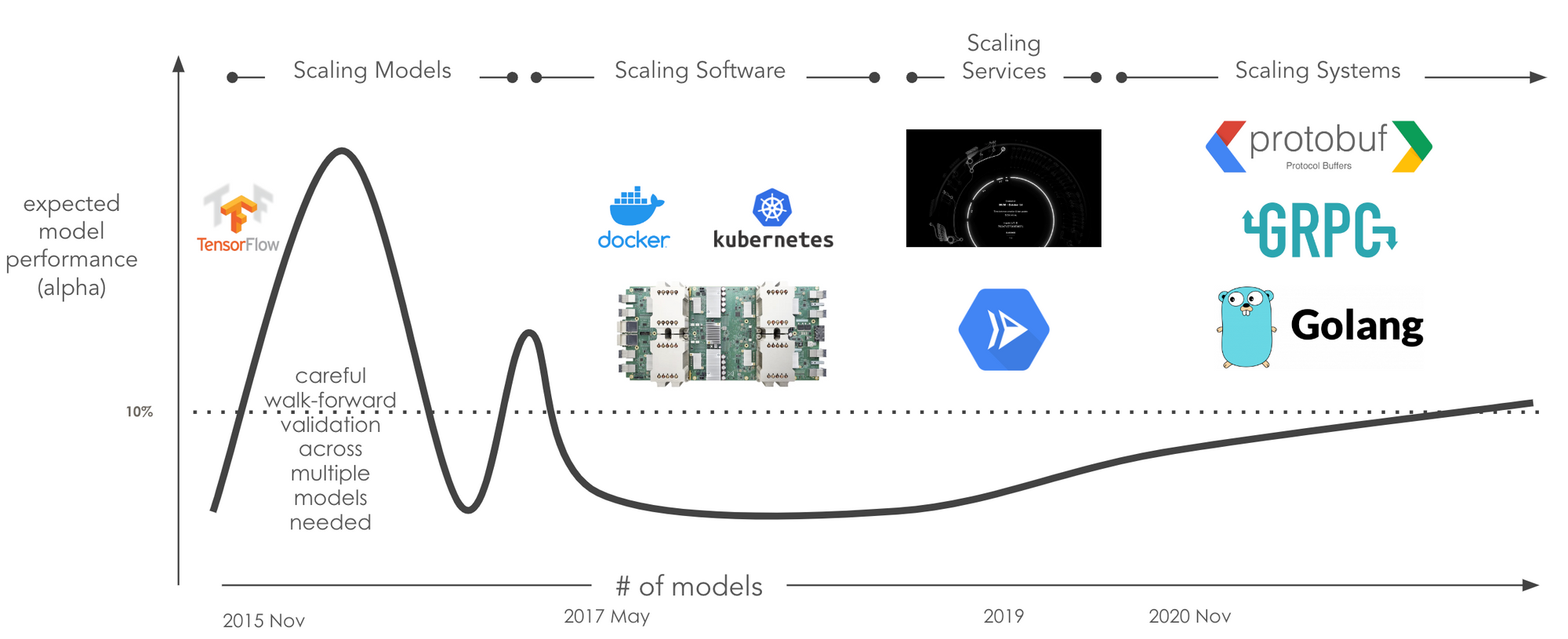
In this memo, I will share some of the things we have learnt around scale in our journey of scaling machine learning systems. The image below outlines the 4 main areas of scale we will cover in the next few sections.
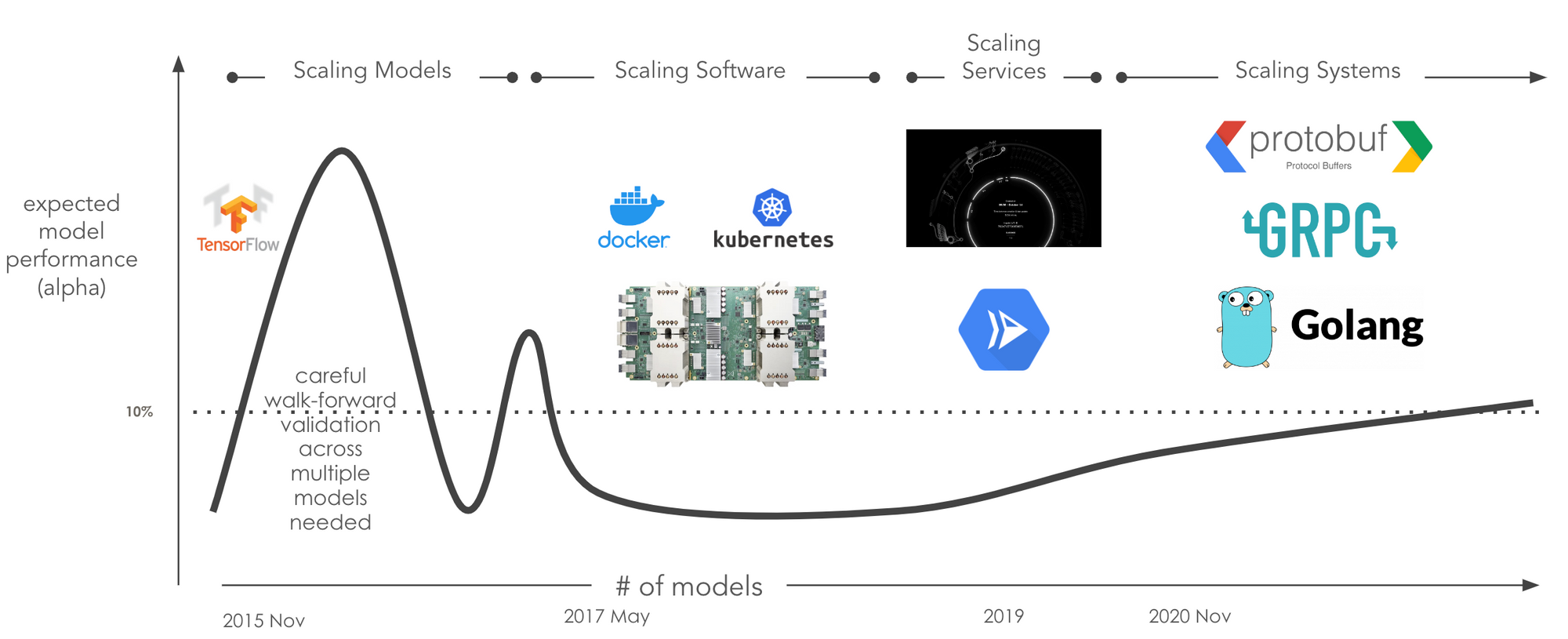
Scaling Models
Google released Tensorflow on November 9, 2015. In the data science / machine learning world this was a big deal. Yes, it was pre version 1.0 and hard to get working, with limited documentation but the thing that resonated with us is the out-of-the-box support for distributed compute. We had model ideas and were able to run them on many machines combining CPUs and GPUs.
We were able to scale a model. 🚀
💡What was quite interesting is how the performance of CPUs vs GPUs varied by model architecture. For one of our architectures we found that a distributed cluster of CPUs outperformed higher spec GPUs.
The reason? It turns out a set of convolutional layers we used in the particular model design simply performed better on CPUs.
Scaling Infrastructure
The nature of answering questions using machine learning is exploratory and, to explore ideas, we needed to run many models in parallel. We had to scale the underlying infrastructure on which our models were running.
Fortunately scaling infrastructure is already solved by technologies like Docker and Kubernetes. We moved all our model code into a standard environment (using Docker) and were able to orchestrate many runs in the cloud (using Kubernetes).
Google Kubernetes Engine, Amazon EKS and Azure Kubernetes Service are all examples of managed versions of Docker orchestration tools.
Scaling Services
Running models at scale created a whole new range of scale related challenges.
More complex models required additional services to help with interpretability. We created services to validate feature pipelines, run feature and data pipelines, run feature importance services at scale. In the current cloud environment, this is largely solved through technologies like Envoy and Istio running on serverless technologies like Cloud Run, Azure Functions and AWS Lambda.
This felt cool. We were running 1000s of services of which most scaled to zero when not used. This was a cost effective way to run our services and seemed elegant. Everything was defined through our own internal API layer. In fact, our setup was nicely inline with the Jeff Bezos mandate to the Amazon staff in 2002:
Jeff Bezos, 2002
Scaling Systems
"In the beginning there was a Proto."
Jan Krynauw, CEO Alis Exchange
The one thing that resonated with us throughout the years is this concept of elegance. Using the right tool for the job often creates this layer of elegance. I often describe this to my team the feeling when one pauses, stands back and looks at a particular implementation thinking: "Now this is elegant 😄".
Throughout our journey we were running Machine Learning models in production and trading live portfolios - trading your own models with real money turns out to be the ultimate forcing function in our search for elegance. The cumulative value of small wins of elegance is massive at scale.
As the number of services grew, we ran into our most recent scale challenge: How do we scale this entire setup - ie. how do we scale this system?
We had Swagger files defining and documenting a fairly clean sets of APIs. Documentation felt ok. We had control over the definitions and internally managed the consistency between all the API layers. Something we felt was clean and manageable at the time, felt less elegant at scale.
In some sense, everything reduces to a scale problem.
In our search of yet another version of elegance we came across Protocol Buffers. The concept is super simple: If you care about something define it. Protocol Buffers does this by design.
The irony was that I met one of the authors of Protocol Buffers, Jeff Dean at a Machine Learning Conference in Long Beach California in 2017. At the time I had no idea what a Protocol Buffer was. If only I did 😬
Exploring this new landscape introduced a new level of elegance across our entire stack. The combination of tools like Protocol Buffers, gRPC, Resource Orientated Design and Go finally allows us to scale our systems. We defined all our resources and moved all our services to this new Proto-driven approach (away from things like Swagger, REST APIs, graphQL, etc.). The beauty is that we are still able to provide Swagger, graphQL, REST APIs to those who really needs it 🤔, but these technologies no longer drive our definitions.
The acceleration across my team has been and continues to be incredible. 🚀
For more details on the above have a look at our Alis Build platform.